复杂产品制造领域知识自动构建与推理决策技术及应用
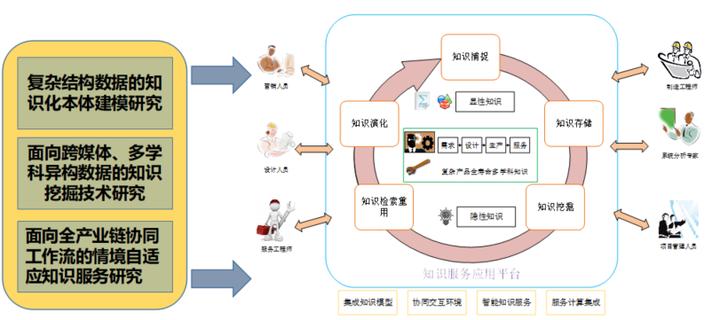
1.1研究目的、意义
人工智能技术、知识工程等技术使得工业数据知识化重用可实现,但制造领域积累的大规模数据来自不同企业、不同单位、不同车间系统,甚至不同领域或第三方平台的数据积累,以不同的格式存储在本地或云端存储中,数据往往处于垂直孤立、分散冗余状态,而单一层级的数据难以满足实际应用。通过数据库的解决方案为数据的规范化组织提供更高的可用性和集中性,但海量的数据使数据库的规模庞大,立足于共享经济下,信息的隐藏更加困难。因此本课题立足全产业链协同工作流,研究不同数据源之间的关联关系,形成跨学科数据共享的协同关系网,构建一致性数据知识模型,为复杂知识服务应用提供基础。
工业上海量的数据中,如航天领域的产品设计档案、船舶领域的航运记录、核电领域的机组运行记录等相关数据,往往以UG、DWT、JPG、WORD、CSV、PDF等格式,甚至一些WAV、MPEG等媒体格式的文件存储,且文件的内部数据格式随着企业管理的改革和技术的革新动态调整,导致规范结构的数据和领域知识子样匮乏,而自动化知识抽取的研究多基于有监督的学习模型进行知识抽取,需要大量规范数据标注集合去训练模型,耗费的人力资源成本巨大,且模型的可移植性差。不同的数据源中,不仅需要解决不同数据源之间的语义冲突,还需解决跨媒体数据的语义层面的耦合,因此本课题立足复杂数据空间,研究知识抽取和知识融合的方法,挖掘复杂产品全寿命周期中的知识,解决多源、跨学科、跨媒体数据的不融合、不共享问题,并通过知识推理技术,构建完善的领域知识图谱。
互联网技术实现以网页为主要形式的服务平台,为业务办理和服务搜索提供极大的便利。围绕信息源和信息检索方式,为用户提供个性化的服务,知识服务作为知识服务平台构建的基础和关键,实现数据知识的积累和重用。现有的知识服务集中电商知识服务领域或公共知识服务领域,对于专业化领域,多应用于简短知识元的检索、推理,难以实现复杂请求的服务匹配,在领域知识支持的服务决策应用上,由于决策依赖于规则和知识体系中直接关系,难以依据多个决策变量形成决策反馈,对于复杂产品全寿命周期过程中复杂的应用环境和不确定性,耗费巨大的成本、资源和时间。本课题以知识图谱为知识服务源,研究语义情境识别技术,挖掘用户的潜在语义信息,实现个性化的知识检索和推荐。面向复杂应用背景,研究多目标决策和群决策理论和方法,构建协同式交互决策模型,并搭建智能服务平台,为智能决策应用提供研究基础。
王宏伟
长聘教授
研究兴趣是人工智能(AI)与基于知识的系统(KBS)应用于复杂系统设计、分析、制造和维护,近年来主要从事知识图谱构建、基于知识的决策与推理、知识驱动的协同建模与仿真、复杂系统状态监测和故障诊断等方面的研究工作